
TLDR; Variation is a useful tactic to apply to Software Testing. Often this is random variation within an equivalence class. We can also vary when performing Exploratory Testing. Consider varying order, data, state, timing.
I found what looks like a potential bug in LinkedIn regarding the hastag processing, and it made me think through how applying a Variation tactic could help.
HashTags
I was planning out some social media posts and investigating hashtags on LinkedIn.
I often use CamelCase for single word representations of multiple word phrases e.g.
- SoftwareTesting
- SoftwareTester
Particularly when I’m writing urls or hashtags.
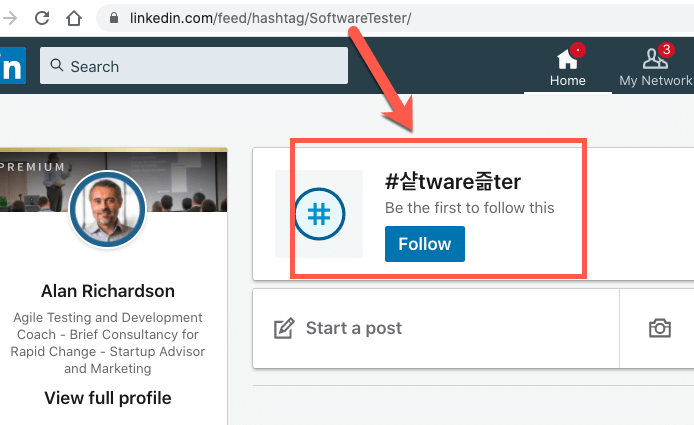
And when I copy and pasted the HashTags I was investigating into the LinkedIn URL, I noticed that CamelCase HashTags were not processed as I had assumed they would.
e.g.
https://www.linkedin.com/feed/hashtag/SoftwareTester
SoftwareTester became 샽tware즒ter
I didn’t expect that.
Encoding
I’m sure there is some character coding explanation that I am not going to investigate.
And I’m sure if I was on a team discussing this we would be discussing:
- multi-lingual support
- character encoding
accept-langagerequest headersaccept-encodingrequest headers
Testing for encoding is very technology and system specific. And can involve some fairly nuanced decisions.
Variation
Instead it made me think of Variation.
Variation is very important in testing.
We often talk about 100% coverage as an impossibility because of the number of combinations we could apply.
This is why I like to introduce Variation into the combinations that I do choose to apply.
e.g.
The above link is to some Java code on Github for a ChangeCaseifier class.
It has a method randomlyChangeCaseOf
I might use it like:
new ChangeCaseifier().randomlyChangeCaseOf("softwaretester);
And then use the returned value to hit a url to see if the variation made a difference.
I used this when writing tests against my API e.g.
String getApiPlayerUrl() {
String theUserName = this.forUser;
//mutation testing for uppercase lowercase handling testing
theUserName = changeCase.randomlyChangeCaseOf(theUserName);
return String.format("/api/player/%s", theUserName);
}
Different runs might call different URLs that I expect the system to process as Equivalent.
/api/player/bob/api/player/bOb/api/player/BOb/api/player/BOB
Note: APIs often do expect urls to be case sensitive and /api/Player/bob might be expected to be different from /api/player/bob. If so, they are not in an equivalence class and we would not use this tactic.
Because I don’t expect the case of the URL to make a difference to how my application processes it.
Rather than try and test all combinations of letters that might be used in the URL.
I added variation into the combinations that I was choosing to test.
In the LinkedIn URL I expected the ‘data’ part of the URL to be processed equivalently, regardless of the case used.
Equivalence Classes
In traditional testing terminology. I identified the variations of username in the URL as an equivalence class.
I expected every upper and lower case variation of a specific username to be processed the same as every other variation.
Equivalence classes are a useful place to add variation into automated execution on repeated runs. When the automated execution is stable. To increase the data scope being used in testing.
Because the variation is happening within an Equivalence Class, we expect the processing of each variation to be equivalent. So if something fails we may have hit upon an ’edge case’ or an assumption that we did not realise we were making.
Very often we have a fixed sampling approach to an Equivalence Class i.e. because it is an Equivalence Class it doesn’t matter which values we pick, so if we pick these three values from this set of 100 values we will be fine.
Randomisation allows us to increase the coverage, and test our assumptions behind the equivalence class.
And we can often do it, when automating, with very low cost.
Non-Data Variation
Opportunities for varying do not need to apply to ‘just’ Data.
I could, when filling in a form, choose to vary the order that I complete the fields:
- name, email, address, submit
- email, name, address, submit
- address, name, email, submit
This might show different messages on screen at different times, but in terms of the ‘submit’ event, the ‘order’ probably shouldn’t matter so the order could be viewed as ’equivalent’ provided the final state of ‘all complete’ is met.
Treating ‘sequence’ as a variable can often return dividends when testing because forms and applications often make assumptions about the order the people use to complete forms.
The underlying point being: apply variation to order, as well as content.
This could be viewed as ‘state’ equivalence if we had modelled the form or interaction as a state machine.
What else?
So much of our interaction with system is part of ‘implicit’ Equivalence Classes. That we often don’t even consider as something that might impact our work.
e.g. The time between completing one action, and moving on to the next.
Time very often has very little variation when automating.
We often want our execution to run as fast as possible so we deliberately try to minimise the amount of time between actions.
We could ‘vary’ the time between actions and see if it makes a difference.
We often get this variation for ‘free’ when we interact with the application during exploratory testing, but we may not recognise it as a potentially important source of variation and not exploit it.
Look for Variation
Look for opportunities to add variation into your testing.
Remember the Requisite Variety lesson from Cybernetics:
- “only variety can absorb variety” - Stafford Beer
- “only variety can destroy variety” - Ross Ashby
The more we apply variety to a system, the more we can see if it has the ability to survive.