
TLDR; Historically we modelled testing as something that we wanted to automate, but the tools didn’t help, so we automated entity management and that has led to a mistaken view of “Test Automation” instead of “Automatization as part of a software development and testing process”.

- Why do we talk about Test Automation the way we do?
- Why do we talk about 100% Test Automation?
- How do we model automation as part of our Test Process?
- How does Testing provide information?
- Why was a Waterfall Test Process Different from an Agile Process?
- Why, in reality, both processes are fundamentally the same.
- How we modelled “Test Automation” incorrectly, and an alternative way to model it.
All this and more…
What does testing do? Provides Information?
This is what we are told.
We need to Unpack this model to understand ‘How’.
How Does Testing Produce Information?

- Testing produces data
- Testers model the data and communicate that model as information
I think of “Information” as something that surprises me. Data only does that when I try to compare it or fit it into a model that I already have.
When communicating to other people, we have to ‘model’ the data as Information, so they can compare it against their model of the subject being discussed.
But its only really Information if it helps them expand or refine their model, otherwise it is just noise or data.
We want the testing process to provide information. Testers, and the people doing testing, convert the data into information.
Basic model of a Testing Process
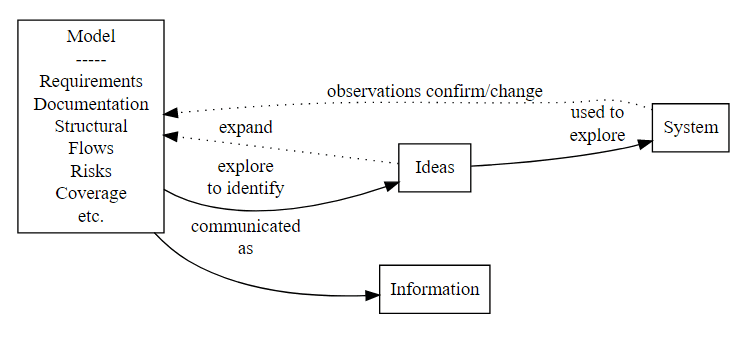
- This is a very Organic Model of testing
- Not very easy to Automate this
- Lots of learning and model building based on observations and thinking
- Comparing a model of a system to the system in order to evaluate the system, create and refine our model, and communicate that model to others
Modelling is key to an effective testing process.
A Traditional Model of Testing Process
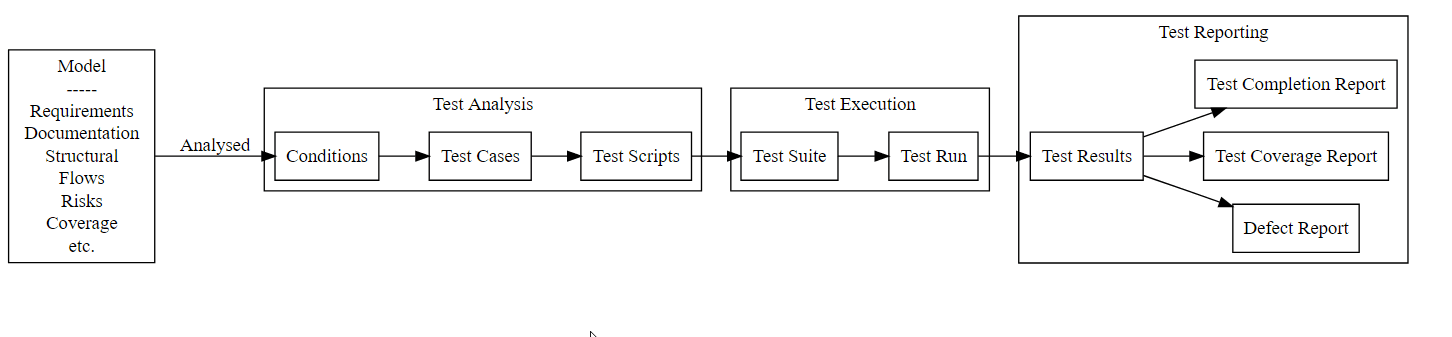
- This is what I learned as a junior tester
- But I wasn’t told that the requirements etc. were actually Models
- This is a key element to understand
- Also this model makes the process look very linear, which makes it very structured and with a formalised set of entities
- How tempted are you to try and automate this process?
- Much more tempted than the more organic, cyclical and learning based process shown earlier.
That’s a bit big, so let’s simplify it, to make it easier to understand

- This is a high level abstraction of the testing process
- But very linear so loses all the notion of feedback and cyclical learning
- Clearly a ‘Test’ process since the word is everywhere
- If we discover any parts of this model that we can automate we will think of it as automating Testing
Now let’s look at that again
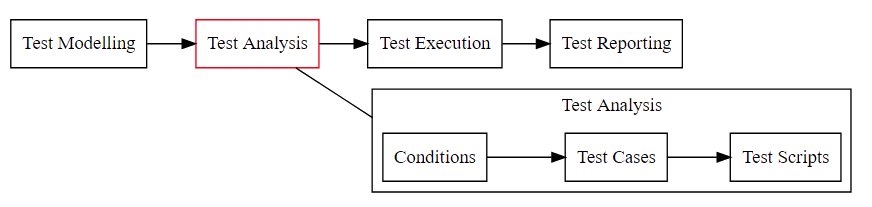
- Analysis is not particularly easy to automate
- Even if we code the Test Scripts we still need someone to write the code
- But we have formalised the entities and we could create standard templates, if it flowed through a process we could create these in advance and run the scripts later
On waterfall projects these entities became necessary because we could not compare our Model of the System to the actual System as it was being developed because it wasn’t ready or runnable for years.
The batch process of development forced, a batch production of Analysis materials that we had to formalise to manage them effectively and cope with multiple people joining/leaving projects over the course of the years of development.
This is not really the sort of efficient process that you want to model in tooling. But that’s what we did.
Let’s explore execution in more detail
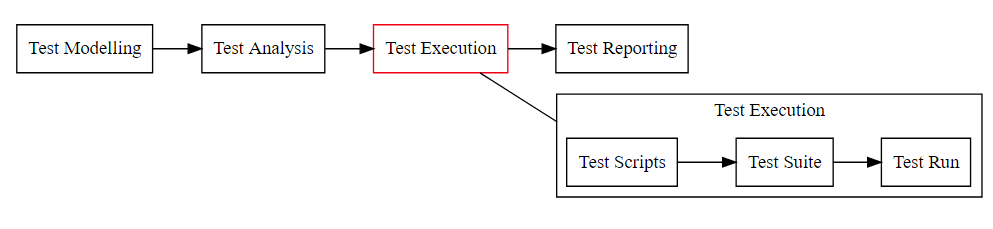
- early automation tools were hard to use, and expensive, and we didn’t always write systems in ways the tools could automate (accessibility layers, standard controls, etc.)
- we could make this process more automated with tool support - forms to fill in to represent the standard entities, databases to store all the data
- since tools were expensive, people performed the execution
- but people are expensive
- so we need cheaper people do to this, therefore make it easy for ‘anyone’ to run these scripts
We really wanted to automate, but couldn’t, so we used all the ‘words’ associated with automating. But then hired people as script interpreters and executors. We skipped all the ’learning and model building during execution’ part of the organic test process.
What about Reporting?
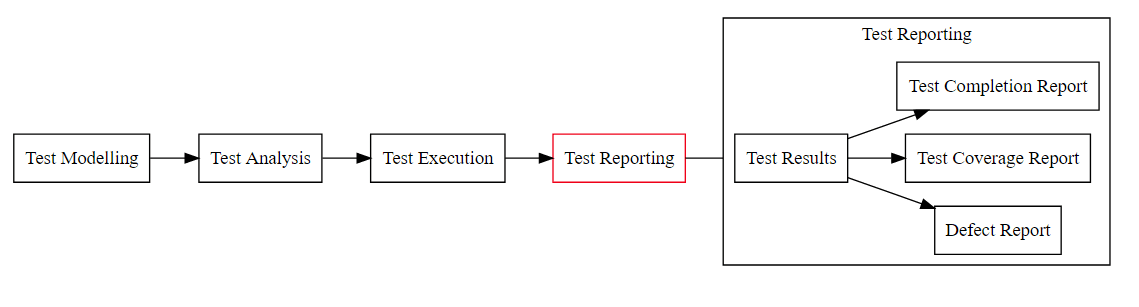
- That’s data - not information
- We can easily automate data creation
- meaningless graphs, standard metrics, it will all look very professional
We can actually track ‘progress’ against plan, because we built everything we were going to do in advance.
Obviously this impacted our ability to adapt as we learned about the software, but we were finding defects and had created so much material to work through that no-one seemed to really mind. And anyway - many projects were cancelled either before testing started, or during the test execution phase that it didn’t seem to matter.
Very easy to create a process support tool to do this
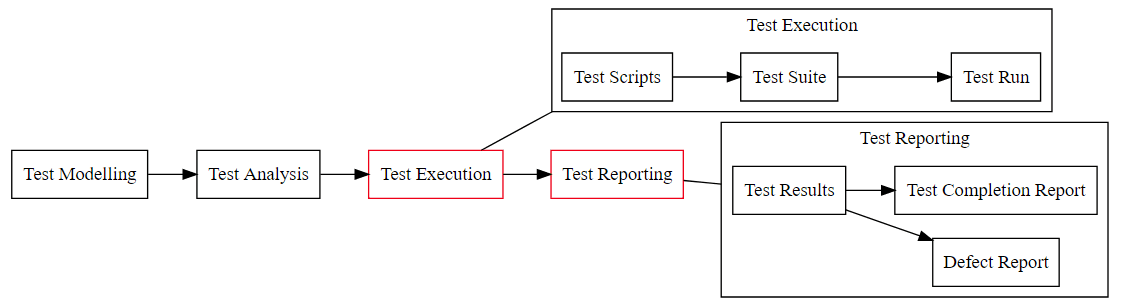
- And look, we just “automated” 50% of our ‘Test Process’
- Later we will figure out how to automatically execute those test scripts
- But we can only track ‘coverage’ against scripts and cases
- some people will then use those numbers to ‘scientifically’ predict:
- how much time is left with testing?
- how many defects are left in the rest of the application?
- some people will then use those numbers to ‘scientifically’ predict:
In order to say we have coverage - we can use the ‘conditions’
We just designed a pretty standard test management tool:
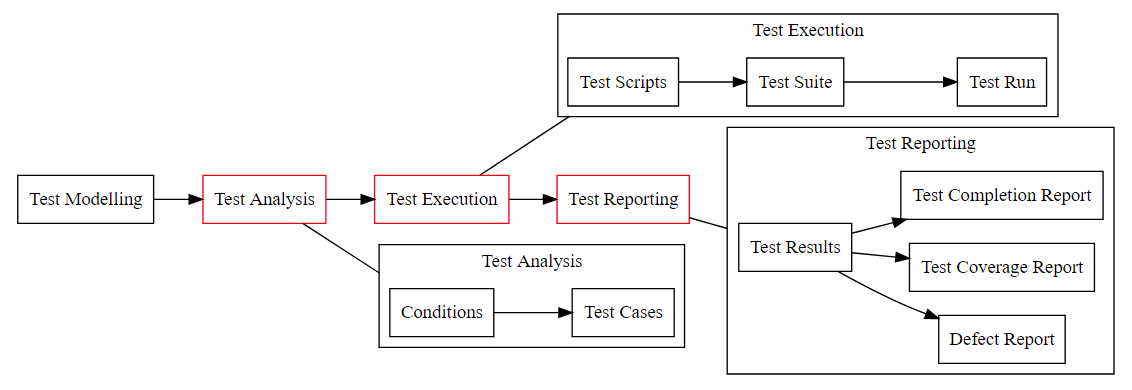
It is easy to see at this point how people might say they can Automate Testing
Let’s re-instate modelling
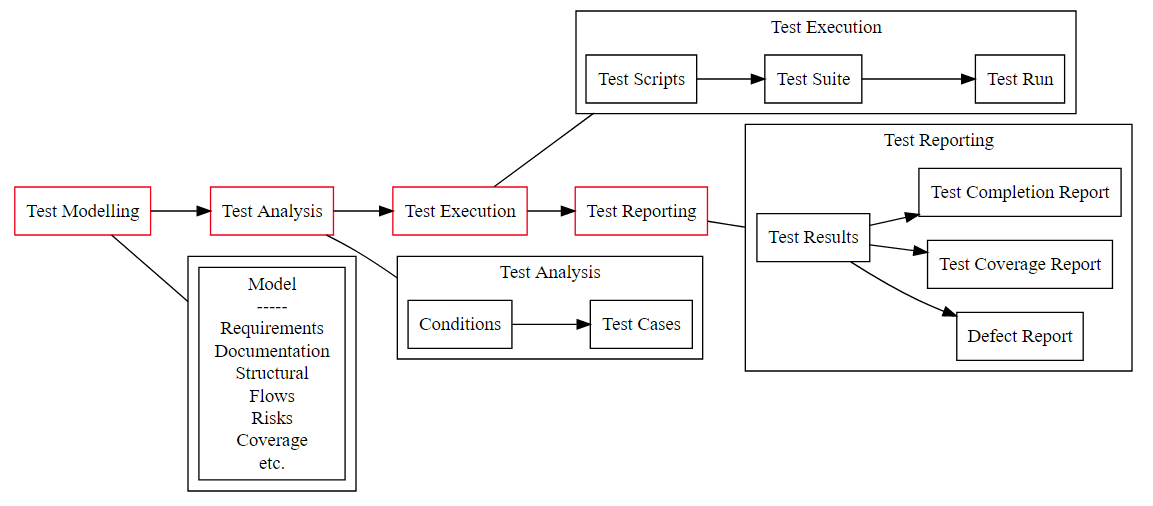
The automated flow is predicated on the notion of “Test Cases” rather than modelling and learning
But we have things in the Models that we haven’t really scripted against, and exploring them and comparing against the system actually makes more sense.
Bring back exploration
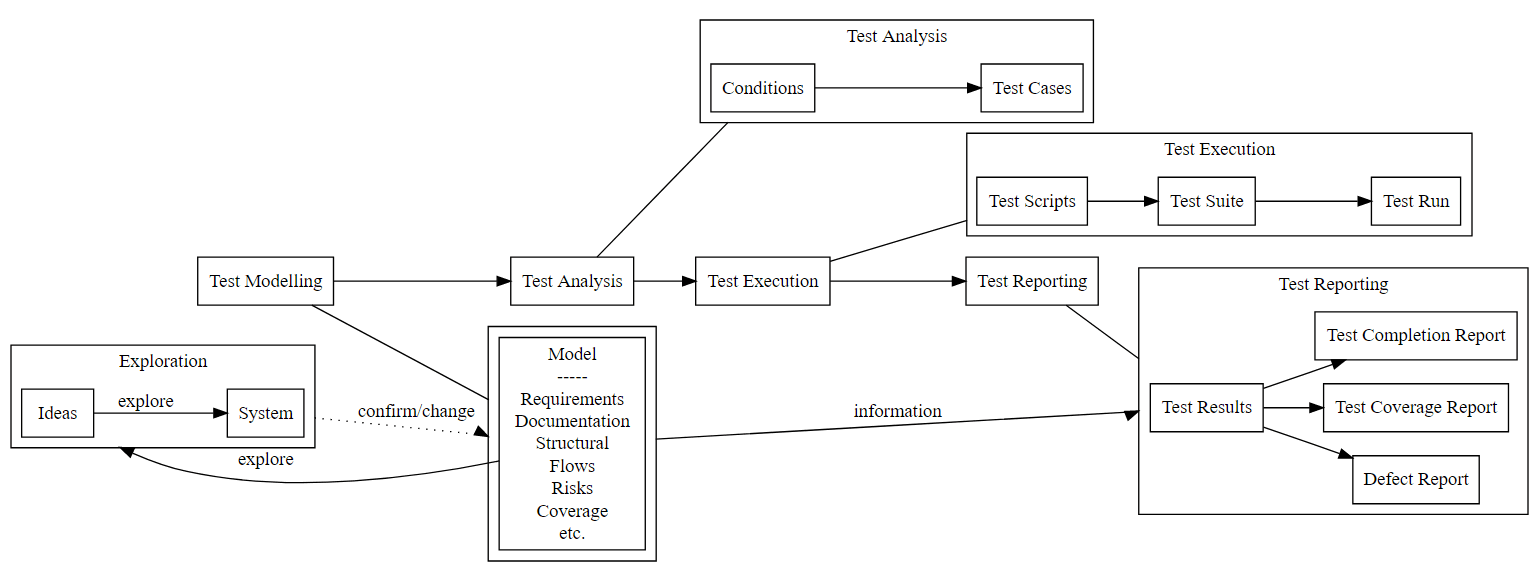
We just added Information and learning back into the Testing Process.
We did actually do this in Waterfall projects because we knew the scripts didn’t cover everything, so as we exectuted them we also did other stuff on the side that we couldn’t tell anyone about to actually make sure we tested the application. In order to raise defects we had to either amend and fudge the scripts or add new test cases and scripts to cover the situation we just tested.
We could have just changed the process, and in some projects we did and formally adopted exploratory testing in combination with scripted testing.
Eventually we stopped writing such detailed Test Scripts. And as tools to automate applications became better and cheaper we were able to write those Test Scripts as code and assert on specific conditions we wanted to check on a more regular and repeatable basis. We called that “Test Automation”.
What if we make it clear what is ’testing’ and what is Automatizable?
The model that we automate is a subset of the model which we use for exploration.
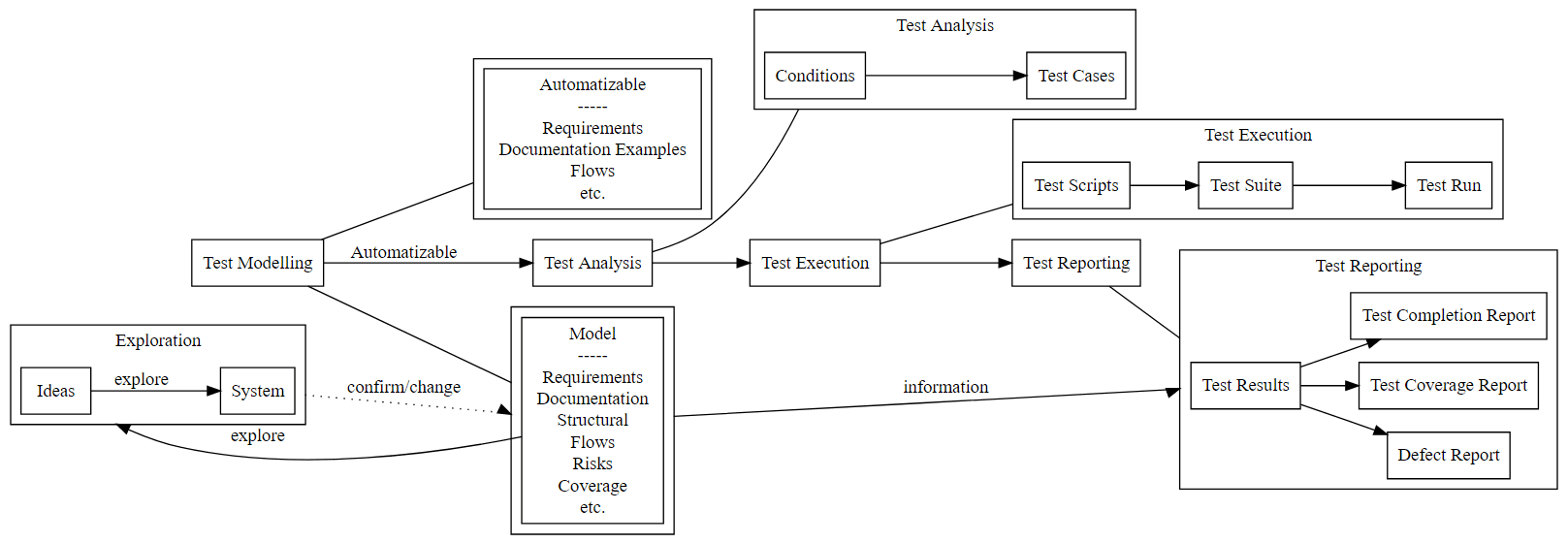
The model shown here:
- Requirements
- Examples
- Flows
- etc.
Maps on pretty well to ATDD, BDD, Specification by Example and Model Based Testing. And we can see that those processes are a subset of our broader model coverage that we want the Test Process to target, fortunately the Exploration process can target that.
And really we are not longer automating “Tests” or “Testing”
We are automating those conditions or requirements or examples or acceptance criteria that we want to see continually checked and asserted on, and the execution data continually reported.
“Test” was just an artifact left over from our earlier models.
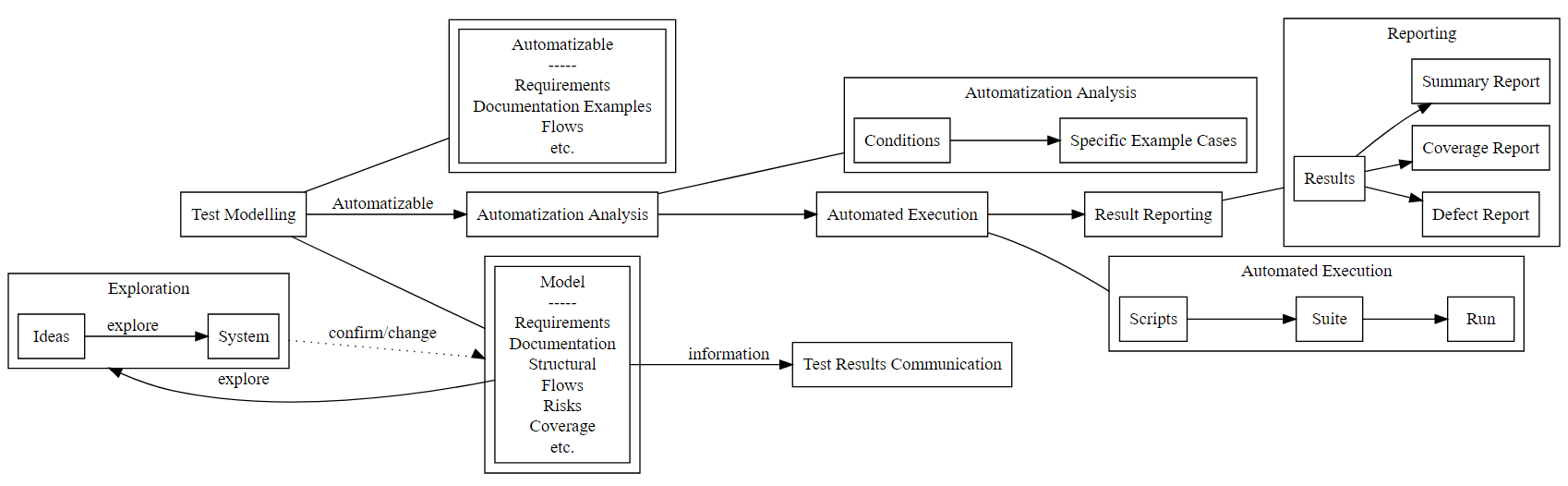
If you model the process that you work with, or the processes you’ve been involved in, what conclusions do you draw from your experience? What information do you gain that will help you refine your model of Testing?
Extras
- All the images in this post were created using GraphViz - specifically WebGraphViz
- The Dot source code for all the images is embedded as html comments within the source code of this page.
Bonus Free Video

